缓存使用得当,可以降低应用的响应时间,减少数据库压力同时节约资源成本。
考虑缓存使用方式前应该思考的问题:
- 系统是读多写少?
- 系统是写多读少?
- 数据变化频率高吗?
两大类:
- cache-aside:数据快照
- cache-as-sor:缓存即为数据源
Cache-Aside
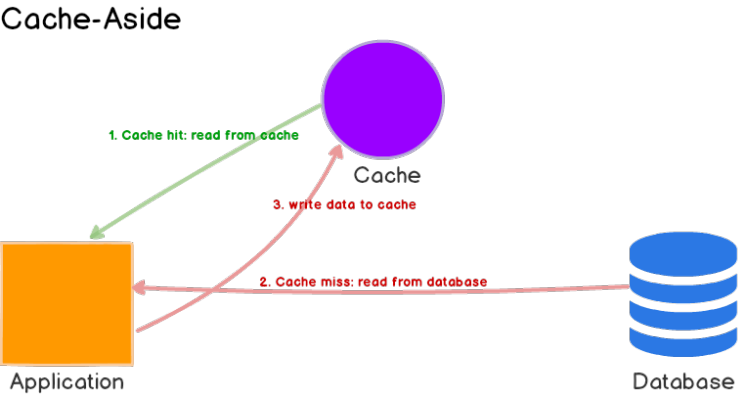
- cashe-aside模式适用于读多的工作场景。
- 使用caceh-aside模式的系统对缓存命中失败有一定的容错率。
- 通过应用来访问缓存和数据库可以解耦数据库和缓存,不需要缓存和数据库的结构保持一致。
- 通过TTL时间来保证cache和database的数据一致性。如果数据一致性需要强一致的话,需要主动失效缓存或者使用其他策略。
Read-Through Cache
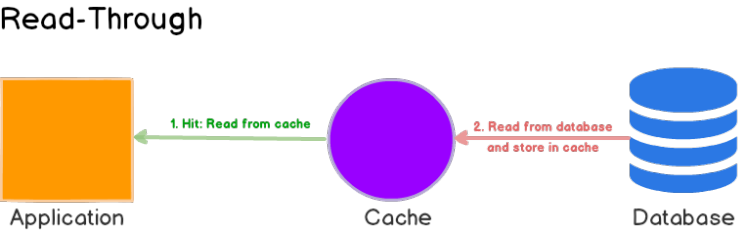
- cache-aside通过application来访问缓存和数据库。read-through通过cache provide来访问数据库。
- read-through的数据结构需要和数据库保持一致
- 参考guava cache的cacheLoader实现
Write-Through Cache
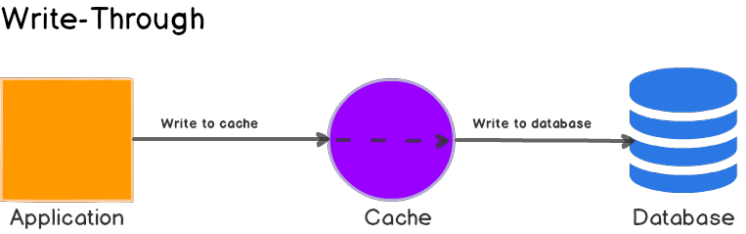
- write-through模式引入了额外的写入性能问题,因为需要先写入cahce,再写回数据库。
- 配合read-through一起使用可以完美发挥这种模式的优势,高效的查询和数据的最终一致性。
- DynamoDB Accelerator(DAX)一个read-through/write-through缓存的典型例子。
write-aroud
先写数据库,数据只有在需要使用的时候才会被加载进缓存,通常配合cache-aside和read-through使用。
write-back(write-behind)
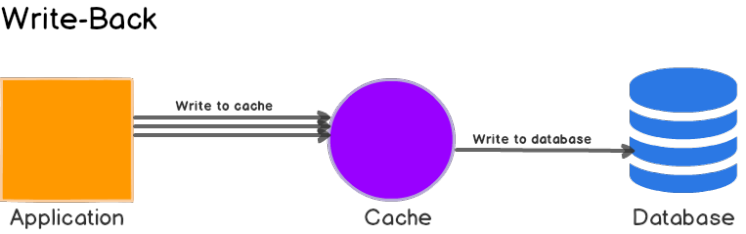
- 先写缓存,最终同步到数据库。适用于写多的场景,例如系统高峰期的写操作。
- 配合cache-aside可以大幅提高峰值读写问题。
- 如果缓存写失败可能或者同步失败可能存在数据丢失问题。
最佳实践
- cache-aside + write-around:适用于大多数缓存使用场景,对缓存未命中存在一定的容错性。
- read-through + write-through/write-back:适用于高性能并发读写场景,如秒杀等。